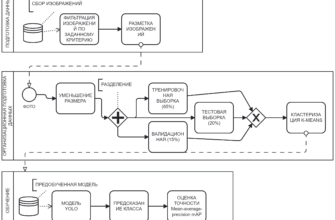
Определение анализа тональности и анализа текста
Анализ тональности (или сентимент-анализ) — это процесс определения эмоциональной окраски текста. Зачем нам это нужно? В современном мире, где информация циркулирует с невероятной скоростью, понимание настроений и мнений людей становится критически важным для бизнеса, медицины и даже политики. Анализ текста, в свою очередь, включает в себя более широкий спектр манипуляций с текстовыми данными, позволяя извлекать смысл и структуру из неструктурированной информации.
Значение этих технологий в современном мире
Анализ тональности и текста стали необходимыми инструментами в арсенале компаний и организаций, стремящихся быть на шаг впереди. Например, с их помощью можно отслеживать общественное мнение о продукции, понимать настроение потребителей в социальных сетях, или даже выявлять предвестники кризисов.
Основы анализа тональности и текста
Ключевые концепции и терминология
Разберитесь в основных терминах: «слово», «фраза», «текст» — это всего лишь верхушка айсберга. Важно понимать контекст, в котором они используются, что и определяет тональность. Тональность может варьироваться от положительной до отрицательной.
Типы анализа тональности
- Положительный: Указывая на положительное восприятие темы.
- Отрицательный: Указывая на негативное восприятие.
- Нейтральный: Никакая явная эмоция не выражается.
Подготовка данных
Сбор и аннотация датасетов
Соберите данные из различных источников, таких как отзывы клиентов, социальные медиа и форумы. Аннотируйте датасеты, чтобы указать на тональность каждого текста. Это позволит вашей модели обучаться на уже размеченных примерах.
Предварительная обработка текста
Перед тем как анализировать данные, необходимо их подготовить для дальнейшего использования. Существует несколько ключевых шагов:
- Токенизация: Разделите текст на отдельные слова и фразы, что упростит его дальнейшую обработку.
- Лемматизация: Упрощайте слова до их корней, чтобы избавиться от различных форм слова.
- Удаление стоп-слов: Уберите часто встречающиеся слова, не несущие значимой нагрузки (такие как «и», «в», «на»).
Векторизация текста
Теперь, когда текст очищен и структурирован, его необходимо преобразовать в числовые векторы для работы с моделями машинного обучения:
- Мешок слов (Bag of Words): Метод, при котором каждая уникальная лексема представляется как признак.
- TF-IDF: Учитывает частоту слова в документе и его распространенность в выборке.
- Word Embeddings: Используйте предобученные векторные представления слов, такие как Word2Vec или GloVe.
Подходы к анализу тональности
На основе правил
Используйте заранее заданные наборы правил и словарей, чтобы определить тональность текста. Это простой и быстрый метод, но недостаточно гибкий.
На основе машинного обучения
Создайте модели, которые обучаются на размеченных данных, позволяя им самостоятельно определять тональность. Это более сложный, но и более точный подход.
Гибридные подходы
Комбинируйте оба подхода для достижения лучшего результата. Например, используйте правила для предварительной фильтрации текстов, а затем применяйте машинное обучение для более точного анализа.
Алгоритмы машинного обучения для анализа тональности
Наивный байесовский классификатор
Это метод, в основе которого лежит теорема Баесова, позволяющая строить вероятностные модели. Он прост в реализации и быстро обучается.
Метод опорных векторов (SVM)
Этот метод ищет оптимальную гиперплоскость, разделяющую различные классы. Выделяется высокой точностью, но может требовать больше вычислительных ресурсов.
Деревья решений и случайный лес
Методы, основанные на иерархической структуре, позволяют интерпретировать принятые решения. Случайный лес, использующий несколько деревьев, помогает улучшить точность.
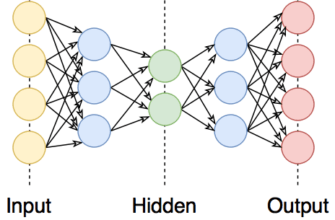
Нейронные сети (CNN, RNN, LSTM)
Нейронные сети могут захватывать сложные шаблоны. Используйте CNN для работы с фрагментами текста и RNN, включая LSTM, для последовательной обработки.
Трансформеры (BERT, GPT)
Современные модели на основе архитектуры «Трансформер» позволяют великолепно обрабатывать текст. BERT идеально подходит для контекстного анализа, тогда как GPT лучше справляется с генерацией текста.
Процесс обучения модели
Выбор архитектуры модели
Определите, какая архитектура будет наиболее эффективной для вашей задачи. Экспериментируйте с различными моделями, чтобы выбрать наилучший вариант.
Разделение данных на обучающую и тестовую выборки
Разделите ваши данные на обучающие и тестовые наборы, чтобы оценить производительность модели на новых данных. Обычно используется соотношение 80/20 или 70/30.
Настройка гиперпараметров
Поэкспериментируйте с различными гиперпараметрами, такими как скорость обучения, количество слоев и т.д. Это поможет улучшить результаты модели.
Методы регуляризации для предотвращения переобучения
Применяйте такие техники, как Dropout, чтобы избежать переобучения модели и обеспечить ее обобщающую способность.
Оценка производительности модели
Метрики оценки
Используйте такие метрики, как точность, полнота и F1-мера, для оценки производительности вашей модели. Это позволит вам понять, как она справляется с задачами.
Кросс-валидация
Применяйте кросс-валидацию для тестирования устойчивости модели на различных поднаборах данных.
Анализ ошибок и улучшение модели
Изучите ошибки, допущенные моделью, чтобы выяснить, где она глубоко ошибается, и направьте усилия на улучшение этих аспектов.
Работа с несбалансированными данными
Методы сэмплирования
- Oversampling: Увеличьте выборку меньшего класса, чтобы сбалансировать данные.
- Undersampling: Уменьшите выборку большего класса, чтобы достичь сбалансированности.
Взвешивание классов
Применяйте взвешивание классов в функции потерь для того, чтобы модель могла лучше работать с несбалансированными данными.
Многоязычный анализ тональности
Особенности работы с разными языками
Учтите, что разные языки имеют свои особенности. Не забудьте дополнительно тренировать модель для каждого языка.
Методы перевода и адаптации моделей
Используйте методы машинного перевода и адаптации существующих моделей для расширения возможностей анализа на другие языки.
Анализ тональности в реальном времени
Оптимизация модели для быстрой обработки
Оптимизируйте вашу модель для работы в режиме реального времени. Это может включать уменьшение объема данных или упрощение архитектуры.
Развертывание модели в производственной среде
После оптимизации, разверните модель в облачной или локальной среде, чтобы реализовать операции анализа тональности в реальном времени.
Обработка сложных лингвистических явлений
Сарказм и ирония
Будьте готовы сталкиваться с сарказмом и иронией в тексте. Эти проявления требуют разработки более сложных моделей, поскольку они могут изменить смысл сообщения.
Контекстно-зависимые выражения
Используйте контекстуально-ориентированные подходы для обработки фраз, чье значение зависит от контекста.
Обработка эмодзи и специальных символов
Учтите, что эмодзи могут нести важную информацию, и их стоит корректно обрабатывать в алгоритмах анализа.
Инструменты и библиотеки
- NLTK: Библиотека для работы с естественным языком, позволяющая выполнять множество задач предварительной обработки.
- scikit-learn: Позволяет легко реализовывать алгоритмы машинного обучения.
- TensorFlow и Keras: Подходят для реализации нейронных сетей.
- PyTorch: Одна из самых популярных библиотек для глубокого обучения.
- Transformers (Hugging Face): Идеальный инструмент для работы с трансформерами и моделями естественного языка.
Облачные решения для анализа тональности
- Amazon Comprehend: Облачный сервис для анализа текстов от Amazon.
- Google Cloud Natural Language API: Инструмент для анализа тональности, доступный в экосистеме Google.
- Microsoft Azure Text Analytics: Обеспечивает API для анализа текстов с использованием возможностей облака.
Этические аспекты и проблемы конфиденциальности
Предвзятость в моделях анализа тональности
Не забывайте, что ваши модели могут перенимать предвзятости, присутствующие в обучающих данных. Важно постоянно проводить аудит и улучшать модели.
Обеспечение конфиденциальности пользовательских данных
Обеспечьте безопасность данных пользователей, особенно при работе с чувствительной информацией, чтобы избежать утечек.
Применение анализа тональности
Мониторинг социальных медиа
Активно используйте анализ тональности для мониторинга и анализа упоминаний о бренде в социальных медиа.
Анализ отзывов клиентов
Анализируйте отзывы о ваших продуктах и услугах, чтобы увидеть, что действительно важно для ваших клиентов.
Финансовый анализ и прогнозирование
Сентимент-анализ также используется в финансовом анализе для предсказания трендов на фондовых рынках, изучая настроения инвесторов.
Будущие направления развития
Мультимодальный анализ тональности
Будущее принадлежит мультимодальным подходам, когда текст, изображение и другие данные будут анализироваться в комплексе.
Интеграция с другими технологиями AI
Объединение анализа тональности с другими областями ИИ, такими как компьютерное зрение и обработка естественного языка, откроет новые горизонты для бизнеса.
Заключение
Обучение моделей для анализа тональности — это сложный, но интересный процесс, открывающий множество возможностей для бизнеса и науки. Исследуйте все аспекты подготовки и оценки данных, а также разрабатывайте свою уникальную модель, чтобы оставаться на шаг впереди. Напишите в комментариях, какие методы вам интересны, и не забудьте поделиться этой статьей с друзьями!
Для получения дополнительной информации о анализе тональности, вы можете посетить следующие ресурсы: