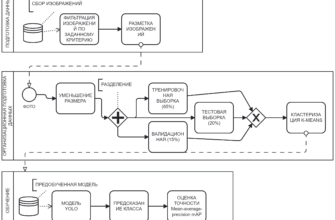
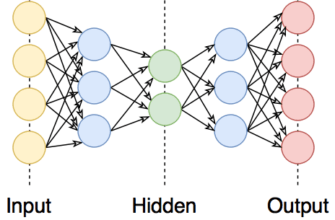
Мир технологий стремительно развивается, и машинное обучение играет в этом процессе ключевую роль. Оно позволяет компьютерам учиться на данных, выявлять паттерны и делать предсказания. Давайте разберемся, что такое машинное обучение и какие существуют основные подходы к обучению — supervised и unsupervised.
Основные концепции
Supervised learning (обучение с учителем)
Supervised learning — это процесс обучения модели на основе размеченных данных, где каждой входной информации соответствует известный выход. Представьте себе учителя, который объясняет ученику, что такое яблоко, показывая примеры яблок и других фруктов. В этом случае алгоритм учится различать, что именно является яблоком.
- Использование размеченных данных: Для обучения требуется большой объем данных с известными ответами.
Unsupervised learning (обучение без учителя)
Unsupervised learning, напротив, работает с неразмеченными данными. Здесь алгоритм сам пытается выявить структуры и закономерности в данных, без подсказок или указаний. Представьте себе археолога, который, найдя кучу древних артефактов, пытается понять, как они связаны между собой.
- Работа с неразмеченными данными: Алгоритм исследует данные и ищет скрытые паттерны.
Ключевые различия
Входные данные
- Supervised: Используются размеченные данные, где каждый пример имеет известный результат.
- Unsupervised: Обрабатываются неразмеченные данные, где алгоритм сам выявляет структуры.
Цели обучения
- Supervised: Основные задачи — предсказание и классификация.
- Unsupervised: Цель — обнаружение скрытых структур и закономерностей в данных.
Процесс обучения
- Supervised: Обучение происходит на основе известных выходных данных, что позволяет модели точно предсказывать результат.
- Unsupervised: Алгоритм самостоятельно выявляет паттерны и структуры в данных.
Типы задач
- Supervised: Регрессия и классификация.
- Unsupervised: Кластеризация и снижение размерности.
Алгоритмы
Supervised learning алгоритмы
- Линейная и логистическая регрессия: Простейшие методы, используемые для предсказания числовых значений или классификации.
- Деревья решений и случайный лес: Алгоритмы, основанные на построении дерева решений для классификации и регрессии.
- Машины опорных векторов (SVM): Используются для классификации и регрессии, особенно когда данные имеют высокую размерность.
- Нейронные сети: Мощные алгоритмы, применяемые в задачах глубокого обучения, таких как распознавание изображений и речи.
Unsupervised learning алгоритмы
- K-means кластеризация: Метод, используемый для разделения данных на кластеры.
- Иерархическая кластеризация: Подход, позволяющий создавать дерево кластеров, начиная от самых мелких и объединяя их в более крупные.
- Метод главных компонент (PCA): Используется для снижения размерности данных, сохраняя как можно больше информации.
- Самоорганизующиеся карты Кохонена: Нейронные сети, применяемые для кластеризации и визуализации данных.
Применение
Области применения supervised learning
- Распознавание изображений и речи: Используется для идентификации объектов на изображениях и понимания речи.
- Прогнозирование: Помогает предсказывать будущие значения на основе исторических данных.
- Медицинская диагностика: Помогает врачам в диагностике заболеваний на основе симптомов и данных исследований.
Области применения unsupervised learning
- Сегментация клиентов: Помогает компаниям группировать клиентов по схожим характеристикам для персонализированного маркетинга.
- Анализ социальных сетей: Используется для выявления сообществ и ключевых влияющих пользователей.
- Обнаружение аномалий: Помогает выявлять необычные или подозрительные события в данных.
Преимущества и недостатки
Supervised learning
- Преимущества: Высокая точность, интерпретируемость результатов.
- Недостатки: Необходимость в большом объеме размеченных данных, что может быть дорогостоящим и трудоемким.
Unsupervised learning
- Преимущества: Способность работать с неразмеченными данными, обнаружение скрытых паттернов.
- Недостатки: Сложность интерпретации результатов, менее точные предсказания по сравнению с supervised learning.
Оценка эффективности
Метрики для supervised learning
- Точность, полнота, F1-мера: Используются для оценки качества классификации.
- Среднеквадратичная ошибка: Применяется для оценки точности регрессии.
Метрики для unsupervised learning
- Силуэтный коэффициент: Помогает оценить качество кластеризации.
- Внутрикластерное расстояние: Используется для оценки плотности кластеров.
Выбор между supervised и unsupervised обучением
Выбор подхода зависит от задачи и доступных данных. Если у вас есть размеченные данные и вы хотите получить точные предсказания, используйте supervised learning. Если же у вас есть много неразмеченных данных и вы хотите найти скрытые паттерны, стоит обратить внимание на unsupervised learning.
Гибридные подходы
В реальном мире часто используется комбинация обоих подходов. Полу-контролируемое обучение (semi-supervised learning) сочетает в себе элементы supervised и unsupervised, что позволяет эффективно работать даже с ограниченным объемом размеченных данных.
Заключение
Supervised и unsupervised learning — это два ключевых подхода в машинном обучении, каждый из которых имеет свои особенности, преимущества и недостатки. В будущем, с развитием технологий, эти методы будут играть все более важную роль в различных сферах нашей жизни. Если вас заинтересовала эта тема, поделитесь статьей в соцсетях и оставьте комментарий с вашими мыслями и вопросами!